
JavaScript в 9 раз хуже HTML для краулинга и рендеринга Google (эксперимент)
Может ли Google просматривать JavaScript-контент? Конечно! Но краулит ли он содержимое JavaScript так же хорошо, как HTML? Отнюдь.
Зиемек Бучко, главный специалист по маркетингу компании «Onely», в конце 2022 года провёл эксперимент, который продемонстрировал, что Google потребовалось в 9 раз больше времени для краулинга JavaScript-страниц, по сравнению с обычными HTML-страницами.
Это показывает существование очереди рендеринга в индексирующем конвейере Google и то, как ожидание в этой очереди может резко повлиять на скорость сканирования и индексации вашего контента.
И это ещё одна причина для того, чтобы перевести как можно больше вашего контента в обычный HTML.

А спонсором блога в этом месяце выступает сервис Rookee. Когда требуется комплексное поисковое продвижение, реклама в Telegram или формирование репутации в интернете – на помощь приходят Rookee!
Эксперимент
Зиемек хотел проверить, сколько времени потребуется Google, чтобы просмотреть набор страниц с JavaScript-контентом, и сравнить показатели с обычными HTML-страницами.
Если бы Google мог получить доступ к определённой странице только по внутренней JavaScript-ссылке, то можно было бы измерить, сколько времени потребовалось роботу поисковой системы, чтобы добраться до этой страницы, проанализировав логи сервера, на котором расположен сайт.
Поэтому, вместе с Марчином Горчикой, SEO-специалистом компании «Onely», Бучко создал поддомен на сайте с двумя папками. В каждой папке был набор страниц, подобных этой:
Контент был сгенерирован искусственным интеллектом.
Одна из папок (/html/) содержала страницы, построенные только на HTML. Это означает, что Googlebot мог перейти по внутренней ссылке на следующую страницу без использования дополнительных ресурсов или рендеринга.
В то же время папка /js/ содержала страницы, которые загружали всё своё содержимое с помощью JavaScript (без использования каких-либо JavaScript-фреймворков). То есть, пока Google не получит дополнительный файл сценария JavaScript (который использовался на всех страницах в папке) и не отрендерит эти страницы, выполнив JavaScript, он будет видеть, в основном, пустую страницу:

После рендеринга JavaScript, Google обнаруживал сгенерированный искусственным интеллектом контент, похожий (но отличающийся!) на контент в папке /html/, а также внутреннюю ссылку, как и в случае с HTML-страницами.
В обеих папках было в общей сложности семь страниц, шесть из которых были доступны только по этим внутренним ссылкам. Экспериментаторы отправили уведомление Google о существовании первой страницы в каждой папке, а затем подождали, пока все страницы будут просмотрены роботом.
Результаты
Чтобы добраться до последней, седьмой страницы папки JavaScript, Google потребовалось 313 часов. В случае с HTML это заняло всего 36 часов. Что почти в 9 раз быстрее.
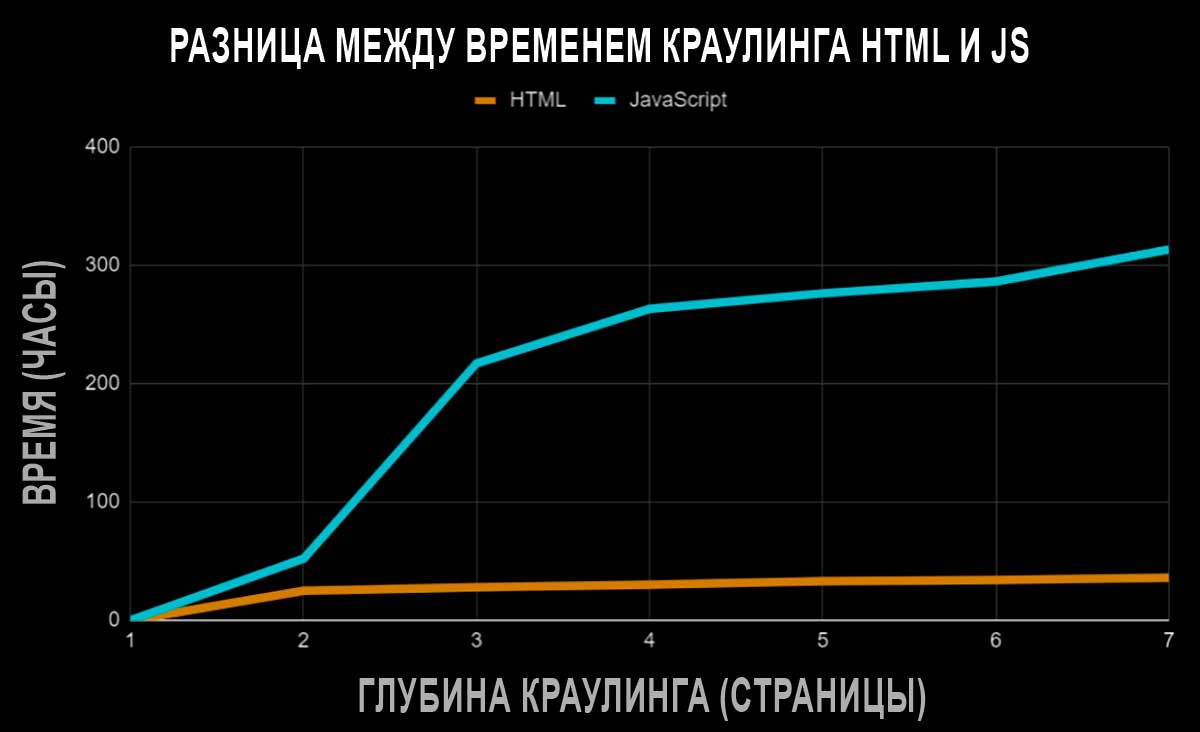
Задержка варьировалась в зависимости от того, насколько глубоко Googlebot проник на экспериментальные страницы, но она всегда была значительной.
Даже при использовании первой внутренней ссылки с JavaScript, Googlebot потребовалось в два раза больше времени, чтобы пройти по ней, чем по HTML-ссылке (52 часа против 25 часов). По мере углубления в папки, задержка становилась всё более значительной.

Выводы
Достаточно неожиданно, что результаты получились настолько разными для JavaScript и HTML.
По сути, в этом эксперименте измерялось то, сколько времени требуется Googlebot для перехода по ссылке в контенте, загруженном с помощью JavaScript, по сравнению со ссылкой в обычном HTML-контенте.
Теперь мы с вами знаем, что разница очень существенна. Но остается вопрос: почему?
Обычно возможным объясняющим фактором является краулинговый бюджет. Каждый дополнительный файл, необходимый для рендеринга страницы, является дополнительным запросом, который Googlebot должен сделать, что увеличивает краулинговый бюджет. Как сказал Эрик Хендрикс из Google во время WMConf 2019: «объём краулинга увеличится в 20 раз, когда я запущу рендеринг»:
Но в случае данного эксперимента присутствовал всего один JavaScript-файл, который был необходим для рендеринга на всех страницах. Google запросил этот файл только при просмотре первой и второй страницы в папке /js/. Не кажется разумным, что один дополнительный запрос заставил Google потратить в 9 раз больше времени на просмотр папки /js/.
По этому поводу Мартин Сплитт сказал следующее во время саммита разработчиков Chrome в ноябре 2019 года:
В прошлом году Том [Гринуэй] и я были на этой сцене и говорили вам: «Ну, вы знаете, это может занять до недели, мы очень сожалеем об этом». Забудьте об этом, хорошо? Потому что новые цифры выглядят намного лучше. Мы проанализировали цифры и выяснили, что, оказывается, в среднем время, которое мы потратили между краулингом и рендерингом результатов, составляет – в среднем – пять секунд!
Если это действительно так, то это означает, что в данном эксперименте произошло следующее (давайте поговорим о том, как Googlebot перешёл со второй на третью страницу в папке /js/, просто для наглядности примера):
- Вторая страница была просканирована.
- Через 5 секунд (в среднем – пусть это будет час!) вторая страница была отрендерена, и Google нашёл ссылку на третью страницу.
- Третья страница была просканирована после 164 часов ожидания в очереди.
В то же время третья страница в папке /html/ была просканирована через три часа после обнаружения второй страницы. После 165 часов прошло 129 часов с тех пор, как Googlebot обнаружил последнюю, седьмую страницу в этой папке!
Можно сделать вывод, что Google придаёт меньшее значение краулингу страниц, связанных JavaScript-ссылками. Но в этом нет никакого смысла – зачем Google отдавать меньший приоритет краулингу ссылок, которые всё равно уже были обнаружены?
В результате у авторов этого исследования остаётся только одно объяснение…
Очередь рендеринга
Между краулингом и рендерингом страницы существует значительная задержка, поэтому Google потребовалось так много времени, чтобы обнаружить и просмотреть страницы в папке /js/.
Поскольку рендеринг требует дополнительных вычислительных ресурсов, страницы, требующие рендеринга, должны ожидать в очереди рендеринга, в дополнении к очереди краулинга, которая применяется ко всем страницам.
Конечно, Google может назначить более высокий приоритет рендеринга для популярных страниц, и задержка не всегда будет такой значительной. Но прежде чем вы решите, что для вас это не проблема, проведите эксперимент на своём сайте и проверьте, сколько времени ваши страницы проводят в очереди рендеринга.
Главный вывод: очередь рендеринга вполне реальна и может значительно замедлить процесс обнаружения Googlebot контента на вашем сайте. Особенно это важно для сайтов, которые публикуют тонны контента и нуждаются в быстрой индексации (например, СМИ).
Если вы используете JavaScript для контента, то, вероятно, лучше всё это делать на стороне сервера. Об этом известно уже много лет, но этот эксперимент – ещё один аргумент в пользу серверного рендеринга в интересах SEO.
Источник информации: onely.com.
СТАТЬИ ИЗ РУБРИКИ:
- Как зарабатывать $25 в день на партнёрке Amazon и Reddit
- Как я устроился на работу SEO-специалистом в европейское агентство
- Как я заработал на перепродаже отзывов для Яндекс и Google карт
- Токсичные ссылки: универсальный список для отклонения через Google Disavow Links Tool
- Мета-теги для сайта онлайн: SEO-инструмент от Рината Хайсмана
- Как раскрутить Твиттер аккаунт до 22000 подписчиков за 7 месяцев и всё потерять
- Продвижение в LinkedIn: 7 уроков из 300 публикаций
- Как зарабатывать на скрапинге сайтов и поисковой выдачи
- Минусовый слив попандер трафика из Индии на пуши и гемблинг (проверяю кейсы)
- 20 зарубежных каталогов сайтов, которые до сих пор можно использовать для линкбилдинга
Думаю, все было так.
Вечером, после тяжёлого рабочего дня, Googlebot получает запрос на индексирования сайта-JS, которые ему не сильно нравится индексировать, так как ресурсы компании для таких целей — ограниченны. Поэтому, почувствовав ещё бо́льшую усталость, бот решил отложить это дело на потом. Но прикол в том, что на носу были выходные, после которых праздники, и бот просто забыл о сайте JS.
Но, Серёга и Ларри не допускают халатного отношения к своим клиентам (сайтам), и об этом бот прекрасно знал. И все же, через несколько сот часов психанул, набрался сил и начал выполнять заказ.
:::
А если серьезно, то думаю стоило бы провести такой эксперимент с 2-3 сайтами. Таким образом каждый следующий эксперимент/сайт подтвердил бы цифры первого эксперимента, ну или создал бы диапазон цифр.
Когда только начал читать статью, подумал, что у Google возможно на такие операции какие-то ограничения.



























