
Google рассказал, почему весь топ-10 занят ворованным контентом
Редактор популярного новостного издания The Verge пожаловался в Твиттере, что их новая статья была заменена в топе Google страницами других сайтов, которые её скопировали.
Почему подобное происходит сплошь и рядом? Отвечает Дэнни Салливан.

А спонсором блога в этом месяце выступает сервис Rookee. Когда требуется комплексное поисковое продвижение, контекстная реклама на автопилоте или формирование репутации в сети – на помощь приходят Rookee!
Скопированный контент разочаровывает некоторых вебмастеров
Копипаста, превосходящая по популярности оригинал, – то, чем вебмастеры недовольны уже много лет. Однако некоторые жалобы вызваны откровенным недопониманием.
Например, когда человек вводит в поиск бессмысленную фразу (случайно выбранные слова из статьи) Google не знает, что делать, поскольку это не настоящий поисковый запрос, и логичного ответа на бессмысленную фразу не существует.
Поэтому поисковая система по умолчанию использует текстовый поиск, что означает, что Google возвращает результаты поиска на основе совпадения слов в поисковом запросе со словами на веб-странице.
Реальные проблемы начинаются, когда скопированный контент занимает более высокие позиции в поисковой выдаче (по сравнению с оригиналом) по конкурентным ключевым словам, которые пользователи действительно ищут.
Должна ли страница ранжироваться дважды, если она находится в результатах Top Stories?
Но с The Verge ситуация иная. Дело в том, что Google не будет показывать страницу в топе обычной органической выдачи, если она уже находится в топе «Главных новостей» (Top Stories).
Top Stories – это дополнительный спецэлемент поиска (вроде избранных сниппетов), в котором Google показывает новостные статьи, связанные с поисковым запросом пользователя.
Поэтому, если вы ищите определённый новостной заголовок, поисковая система, скорее всего, покажет соответствующую страницу СМИ в верхней части результатов поиска в разделе Top Stories.
Но в таком случае Google не показывает оригинальную статью в верхней части обычных результатов поиска из-за дедупликации (алгоритм, который не позволяет одной и той же странице ранжироваться дважды).
Возникает закономерный вопрос: должен ли Google дважды ранжировать одну и ту же страницу: один раз – в Top Stories, второй раз – в верхней части обычных результатов поиска?
Вся первая страница Google состоит из украденного контента
18 января Дитер Бон (исполнительный редактор The Verge) написал у себя в Твиттере, что поиск заголовка одной из его статей привёл к тому, что весь топ-10 Google был занят ворованным контентом (за исключением раздела Top Stories).
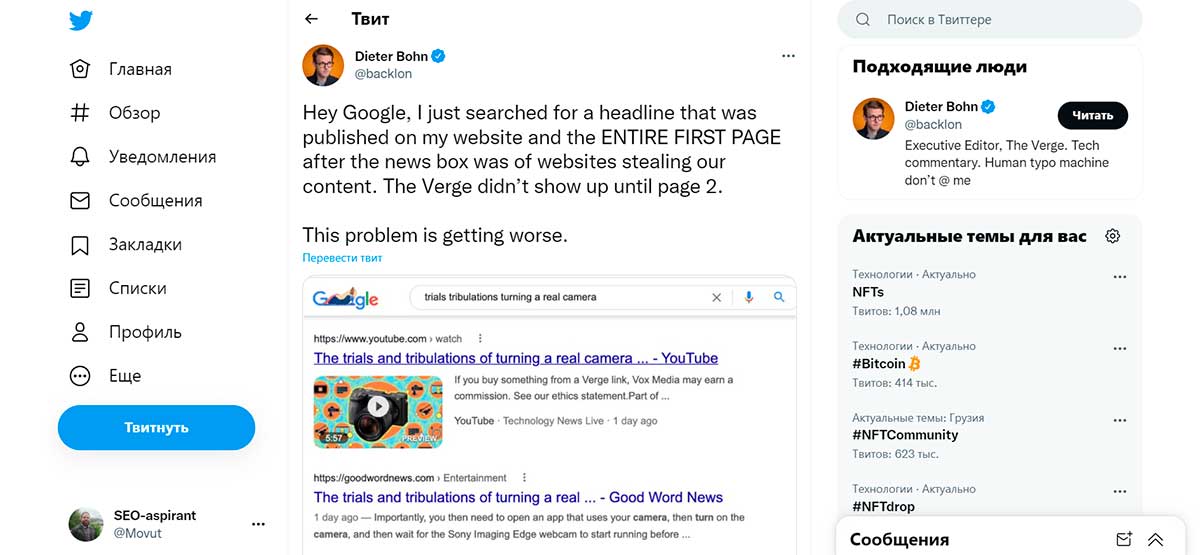
Дэнни Салливан из Google признал, что авторы контента, ищущие его по заголовку, ожидают увидеть свои статьи в верхней части результатов поиска, а не на второй странице.
Но он также отметил, что поиск по заголовку – не обязательно совпадает с тем, как обычные пользователи ищут подобные материалы.

Ответ Салливана сомнителен. Можно привести пример, который его опровергает. Когда люди хотят поделиться статьёй с друзьями или в социальных сетях, они, с большой долей вероятности, ищут именно по заголовку.
Далее идёт объяснение от Дэнни, почему оригинальная статья ранжируется на второй странице результатов поиска Google.
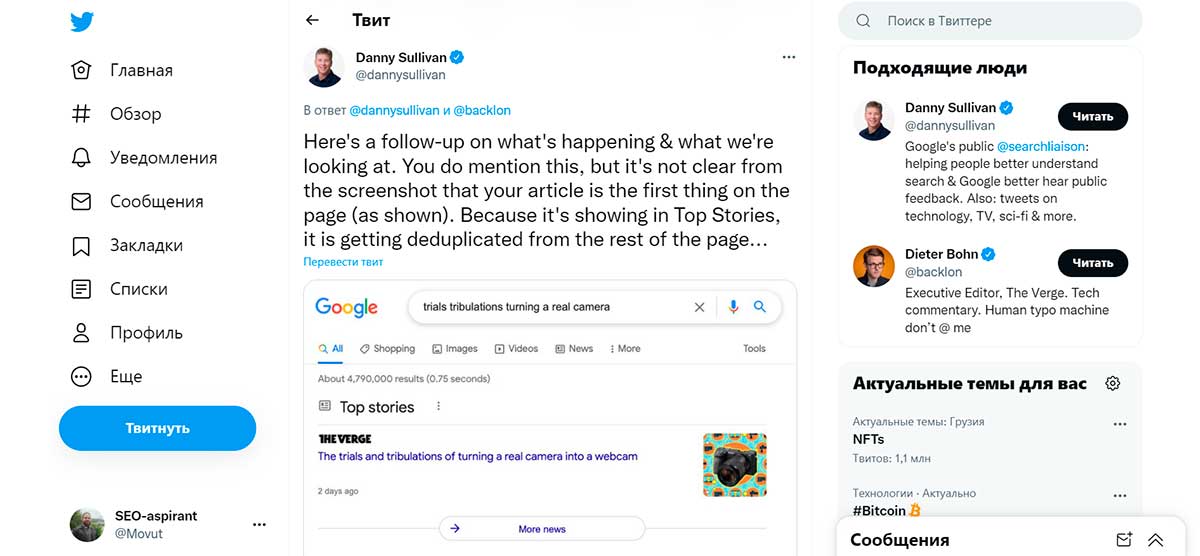
Поскольку статья ранжируется в Top Stories, она дедуплицируется в остальной части поисковой выдачи.

Дедупликация может быть полезна, когда пользователь вбивает в Google слова, соответствующие интенту поиска решения, и первоисточник оказывается в топе «Главных новостей». Плюс, дедупликация подразумевает большее разнообразие.
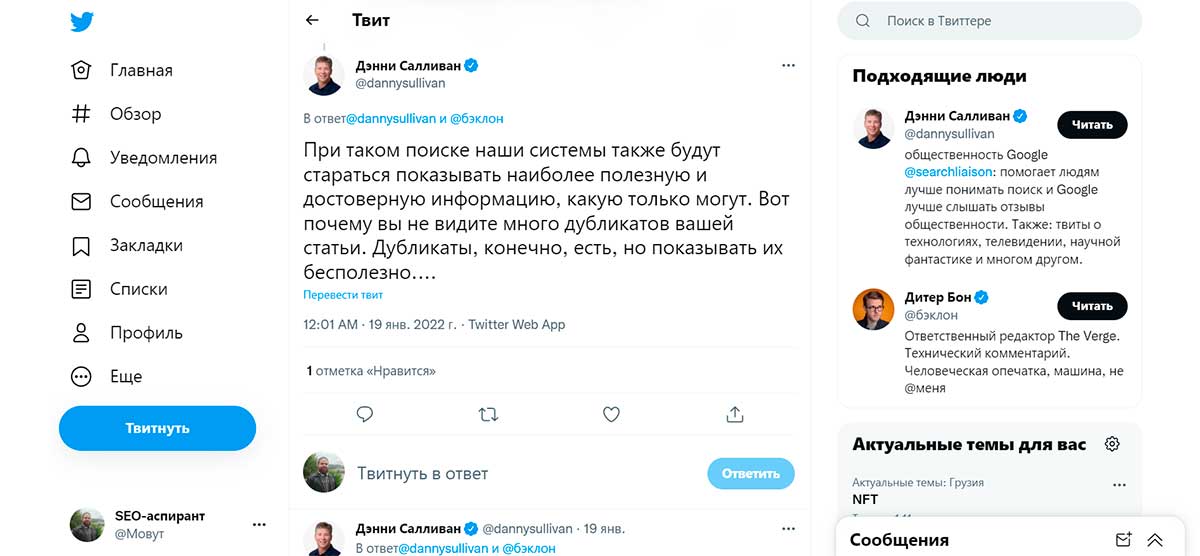
Поисковые запросы, вызывающие альтернативные результаты поиска
Дальше Салливан объясняет, как поисковый запрос с большим количеством слов (например, заголовок статьи) приводит к тому, что нынешний алгоритм Google как бы отключается и начинает выдавать результаты поиска, больше похожие на «старый стиль» (когда SERP не был основан на интенте или ссылках, а просто ориентировался на ключевые слова).
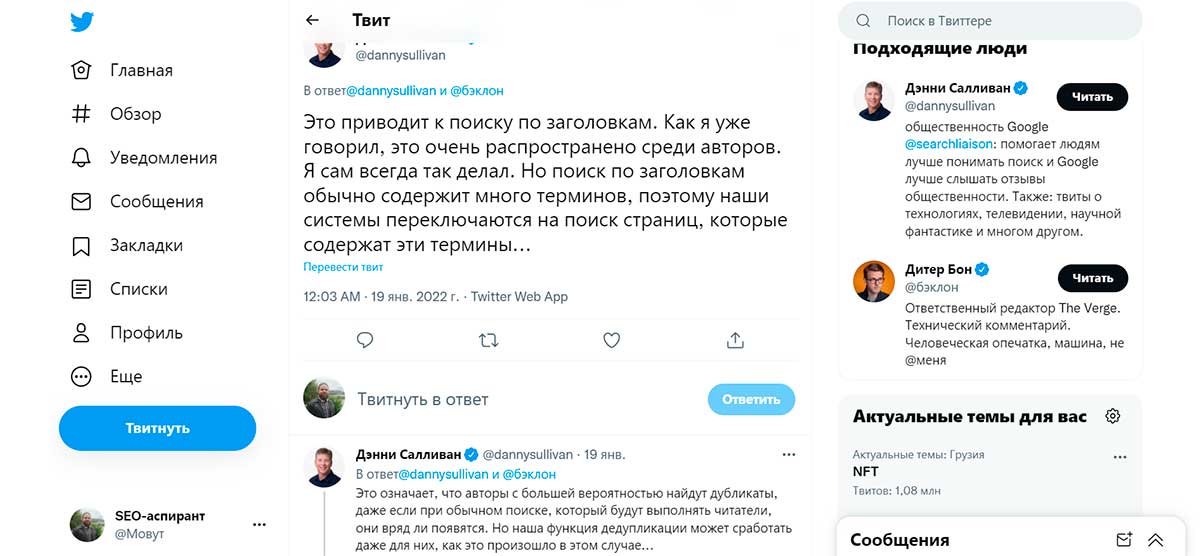
У поиска по заголовкам существует определённое поисковое намерение (интент). Возможно Google в данном случае просто не распознал его. Или не посчитал, что здесь оно уместно.
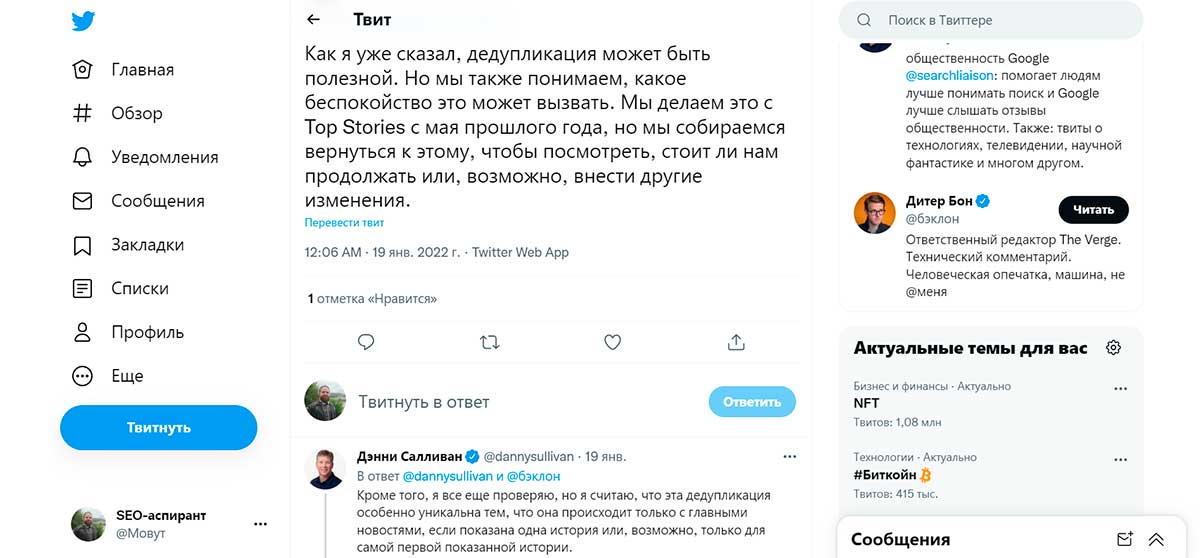
Подытоживая, Дэнни отметил, что Google дедублирует ссылку из классических результатов поиска, если она отображается на первом месте в Top Stories, и если блок Top Stories появляется перед веб-результатами. В противном случае такого не происходит.
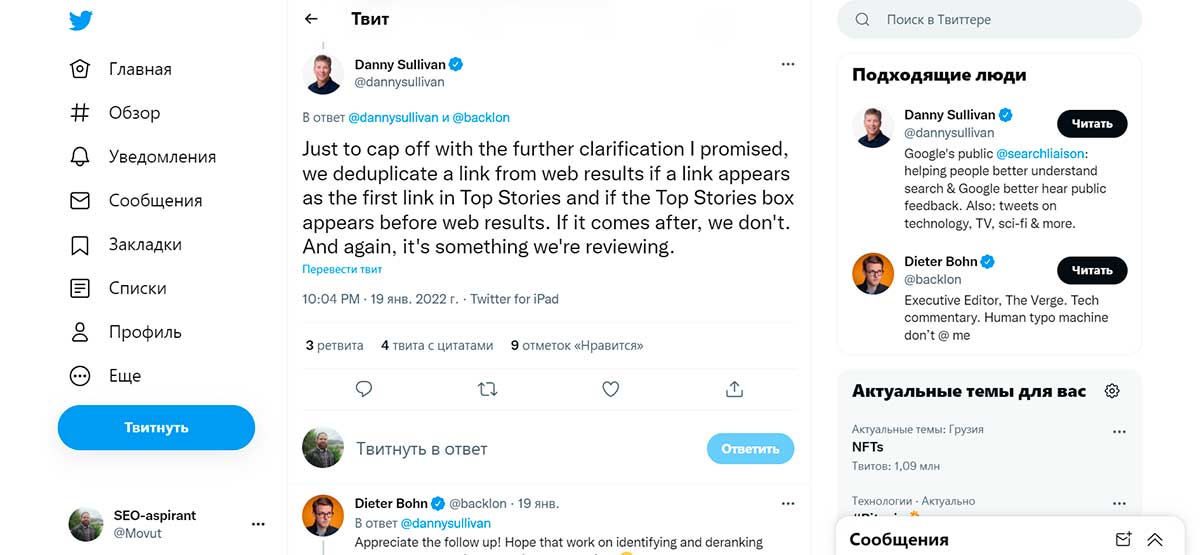
Новостные статьи и дедупликация
Дедупликация (дедубликация) – это когда Google пытается предотвратить двойное ранжирование одной статьи в результатах поиска. Дэнни Салливан заявил, что статья может не появляться в обычных результатах поиска, если она уже занимает место в Top Stories, и если Top Stories располагается в верхней части страницы.
Возникает вопрос: является ли это ситуацией, когда веб-страница должна ранжироваться дважды, потому что пользователь может захотеть увидеть оригинальную статью в верхней части результатов поиска, даже если она уже находится в разделе Top Stories?
Как только раздел Top Stories исчезнет, новостная статья должна занять первое место в результатах поиска.
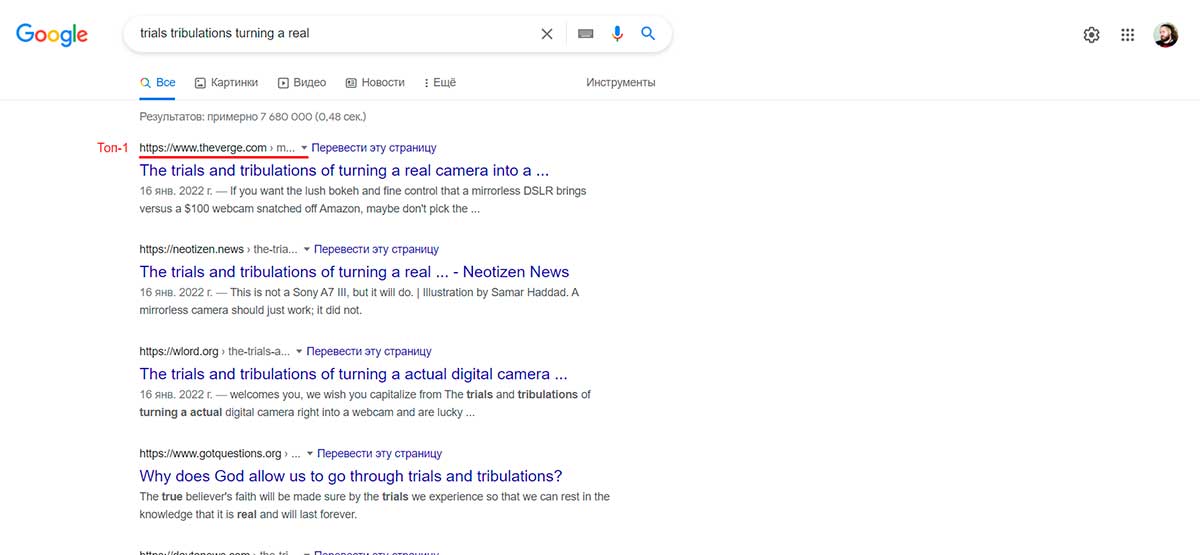
Как видно по скриншоту выше, в данной конкретной ситуации именно так и происходит.
Это достаточно интересный вопрос. В идеале Google должен беспристрастно решить, какой подход к ранжированию будет справедлив, с точки зрения владельцев сайтов, и что в таком случае полезнее самой поисковой системе.
А вы что думаете по этому поводу? Справедливо не пускать в топ сайты, которые уже занимают первое место в Top Stories? Или это должно быть своеобразным бонусом для вебмастеров?
СТАТЬИ ИЗ РУБРИКИ:
- 8 актуальных плагинов WordPress для мобильной версии вашего сайта
- Как помочь Google ранжировать товары с дублирующимися описаниями
- Два типа краулинга Google: Discovery и Refresh
- Google не будет предоставлять подробности обновлений основного алгоритма поиска (core updates)
- Что такое OTT-реклама: руководство по использованию
- Пугающая PPC-статистика для арбитражников и рекламодателей (11 примеров и советы по выживанию)
- Чистый спам или контент для взрослых могут отравить ваш домен
- Google не наказывает за партнёрские ссылки без рекомендуемой разметки
- 5 способов улучшить свои навыки публичных выступлений
- 5 секретов успеха бизнеса Макдоналдс
Из этой новости можно сделать интересный вывод, что нч с длинным хвостом подчиняются законам «старого сео» и должны хорошо отрабатывать в дорах за счет миллионов страниц или в дорогой коммерческой тематике за счет узкой специализации и высокодоходным лидам (реально сталкивался с тематикой, где 3-5 посетителей в сутки по итогу дают 1-5к$/месяц чистого дохода и это в ру, какие варианты бывают в англ или дорогом арабском/европейском интернете даже сложно представить).



























