
Почему корреляционные исследования поисковой выдачи ненадёжны
Корреляционные исследования результатов поисковой выдачи Яндекса и Google проводятся не первый год и стали уже доброй традицией в SEO-сообществе. Но их результаты могут быть ненадёжными с точки зрения того, как поисковики оценивают веб-сайты. В итоге использование такой информации способно навредить вашей стратегии продвижения.

Билл Славски о подводных камнях корреляционных исследований
Специалист по интернет-маркетингу Роджер Монтти (@martinibuster) недавно беседовал в Твиттере с известным западным сеошником, Биллом Славски (@bill_slawski), о корреляционных исследованиях, и тот указал на несколько причин, по которым эти исследования могут привести к неточным выводам.
Вот что конкретно написал Билл:
Одной из проблем является отображение дополнительной информации в результатах поиска, подмешиваемой туда исходя из знаний, основанных на объекте запроса.
При корреляционных исследованиях могут возникать трудности с объяснением этой информации, особенно если не учитывается процесс её формирования. Схожие проблемы появляются из-за спецэлементов.
Или, например, популярные новости наверху SERP. Они там находятся не из-за того, что собрали огромное количество обратных ссылок.
Данные в исследованиях корреляции могут быть очищены таким образом, чтобы в них не появлялись избранные сниппеты, но давно прошли времена, когда выдача представляла собой исключительно 10 синих ссылок.
Не уверен, что видел в последнее время качественных исследований, которые бы учитывали все эти элементы.
Как исследователи будут добывать информацию о главных новостях, которые отображаются в результатах поиска в зависимости от запроса?
У Google есть несколько инициируемых событий, происходящих на основе запроса. Были ли очищены данные для их удаления, поскольку они могут не вписываться в выводы авторов? Я подозреваю, что это может иметь место во многих исследованиях.
Манипулирование данными является вредной практикой, потому что это означает, что результаты исследования отражают выводы, сделанные ещё до его запуска.
Можете посмотреть профиль Славски. В районе 30 апреля он много обсуждал с подписчиками этот момент.

Корреляции, связанные с обратными ссылками
Многие SEO-исследования показывают, что первые позиции в поисковой выдаче тесно связаны с количеством обратных ссылок доменов. Другие указывают на идеальное соотношение анкоров или бэков на домашнюю страницу.
Но есть проблема с такого рода выводами.
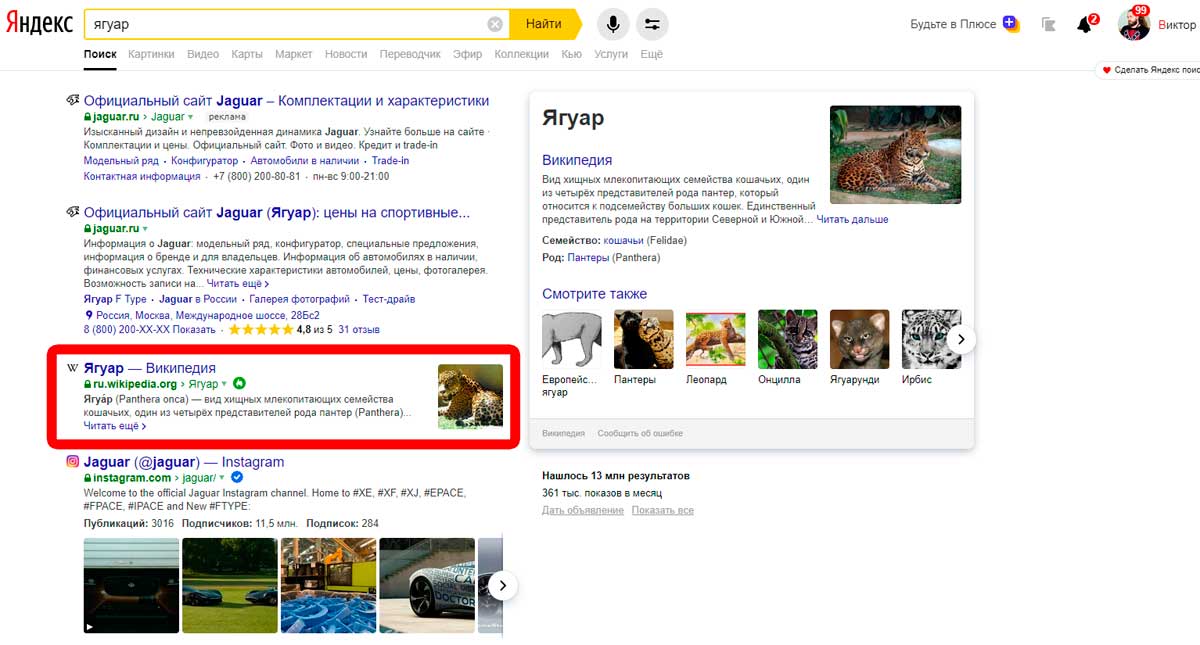
В рамках одного запроса поисковик вам может показывать результаты с совершенно разными значениями. Классическим примером этой реальности является выдача по слову «ягуар».
Один из способов, с помощью которых поисковые системы ранжируют результаты своей выдачи, – это популярность поискового намерения. В случае поисковой фразы «ягуар», наиболее популярным поиском является поиск автомобиля.
Причина, по которой сайт с описанием животного занимает здесь не первую строчку, не имеет никакого отношения к количеству обратных ссылок или соотношений анкоров. Хищное млекопитающее расположилось на втором (а если учитывать рекламу, то на третьем) месте, потому что цель поиска для животного не соответствует цели поиска для автомобиля.
По такому запросу пользователь может искать:
- автомобиль;
- животное;
- автогоночную команду;
- военное спецподразделение;
- футбольный клуб;
- танк;
- фильм;
- отзывы;
- новости;
- видео на Ютубе;
- и ещё кучу всего.
Посмотрите выдачу Яндекса или Гугла по запросу. Из топ-10 пятнистая кошка будет упоминаться раза два – с помощью Википедии и картинок. Всё остальное заполонили дилеры автомобилей «Jaguar».
Это наглядный пример различия поисковых интентов. А теперь представьте, что вы для исследования собираете каким-нибудь SEO-инструментом всё это и пытаетесь связать с количеством обратных ссылок.
Различия поисковых интентов
Практически для каждого поискового запроса существует несколько интентов.
Чем более расплывчат поисковый запрос, тем больше вероятности, что поисковая система будет показывать пользователю спецэлементы, вроде «люди также спрашивают». Это ещё сильнее усложняет корреляционные исследования.
Старая добрая выдача, состоящая из десяти синих ссылок, ушла в прошлое. А исследователи продолжают анализировать SERP, как будто на дворе 2000-й год. В итоге мы с вами получаем не очень достоверную информацию.
Корреляционные исследования игнорируют реальность разнообразия поисковых интентов и многих других современных функций поиска.

В 2020-м выдача выглядит как-то так:
- Топ-1: «официальный сайт А».
- Топ-2: «страница Википедии про А».
- Топ-3: «как сделать А».
- Топ-4: «где купить А».
- Топ-5: «сравнительный обзор А, Б и В».
- Топ-6: «свежие новости про А».
И каждый сайт в примере выше оценивается не по количеству обратных ссылок. Они ранжируются в соответствии с наиболее популярным поисковым интентом.
Это как с запросом «ягуар». На первом месте располагается сайт автомобильной компании не из-за того, что у него больше ссылочная масса по сравнению с Википедией. Он на первой строчке, так как самый популярный поисковый интент для слова «ягуар» – это авто, а не зверушка.
Количество обратных ссылок между позициями 1, 3, 4, 5 и 6 совершенно не имеет отношения к причине, по которой эти страницы ранжируются на этих позициях. Как правило, для каждого заданного поискового запроса существует несколько целей поиска.
Следовательно, любое исследование корреляции, которое делает выводы, основываясь на первой десятке или двадцатке результатов поиска, даст информацию, которая в реальности не отражает то, как поисковик оценивает веб-страницы.
Чтобы попытаться получить более точный результат, научное исследование должно сначала определить различные намерения пользователя и назначить интентам классификацию: информационные, транзакционные, образовательные и так далее.
Но даже после такого разграничения всё ещё останутся белые пятна. Ваша классификация интентов может не совпадать с видением Яндекса или Гугла.
Реверс-инжиниринг не раскроет вам секретов поиска
Разобраться в результатах поиска Google или Yandex с помощью исследований корреляций не так-то просто, по причинам, изложенным выше.
Корреляционные исследования всегда были ненадежными. И всё же многие люди продолжают слепо в них верить. Возможно, из-за крутых кликбейтных заголовков?
А что вы думаете на счёт таких исследований? Возможно, SEO-сообществу пора от них полностью отказаться? Делитесь своим мнением в комментариях!
СТАТЬИ ИЗ РУБРИКИ:
- Влияние обратной ссылки может меняться со временем
- Топ 5 советов для успеха в блогинге от 1001 блогера [исследование]
- Как продвинуть видео на Ютубе в 2020 [7 новых тактик]
- Мета тег Description: как заставить Google использовать ваш вариант
- Маркетинговая контент стратегия 2020 от Брайана Дина aka Backlinko
- Как COVID-19 влияет на электронную коммерцию и арбитраж трафика
- Новые советы от Google по поводу алгоритма Page Layout
- 165 советов по электронной коммерции от Дэна Баркера
- Влияние нулевой позиции на CTR сайта в поисковой выдаче Google [исследование от Perficient Digital]
- Как работают алгоритмы Instagram в 2020 году






























